今回の社員ブログのテーマは「【Python】Heliumでブラウザ操作を自動化してみよう」です。
ブラウザ上で行う、テキストを入力したりボタンをクリックしたりといった操作を自動化するツールで有名なものに、Selenium(セレニウム)があります。さまざまなプログラミング言語で使用できるのが特徴で、書籍でもよく紹介されています。このようなツールは、いわゆるRPAや業務の自動化に活用できます。
Pythonでは、このSeleniumのラッパーとして、Helium(ヘリウム)というライブラリがあります。
現状、ChromeとFirefoxのみ対応していますが、Seleniumよりコードを短く書けるというメリットがあります。そのため、Heliumを使ったブラウザ操作の自動化を行ってみようと思います。ここでは、以下の操作を自動化します。
- ブラウザで「https://www.google.com/?hl=ja」を開く
- フォームに「Python」を入力する
- ENTERキーを押下
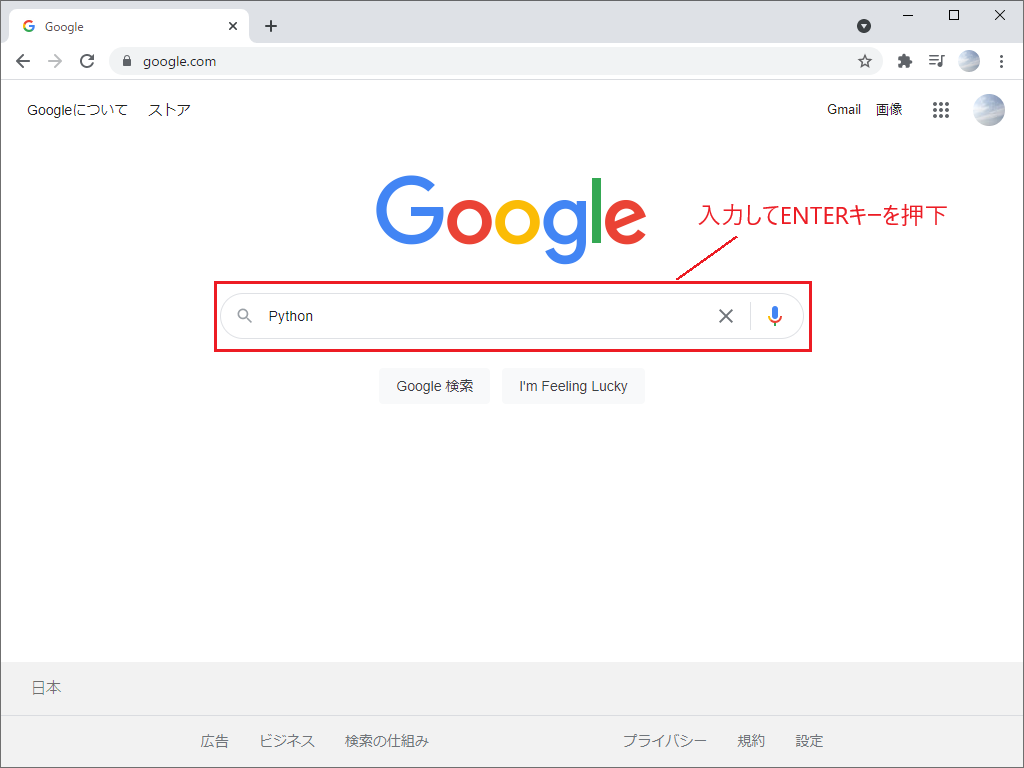
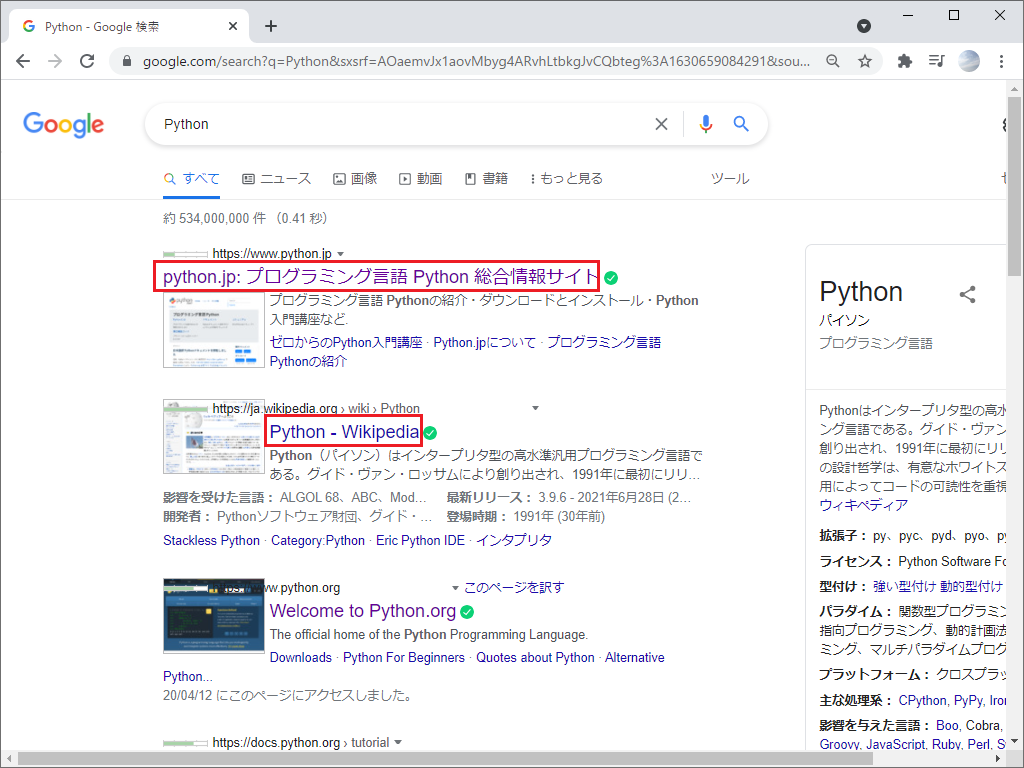
- 表示された1ページ目の検索結果の記事タイトルを取得する
なお、検証はWindows 10+Google Chromeで行いました。
HeliumでGoogle検索を自動化してみよう
①Heliumのインストール
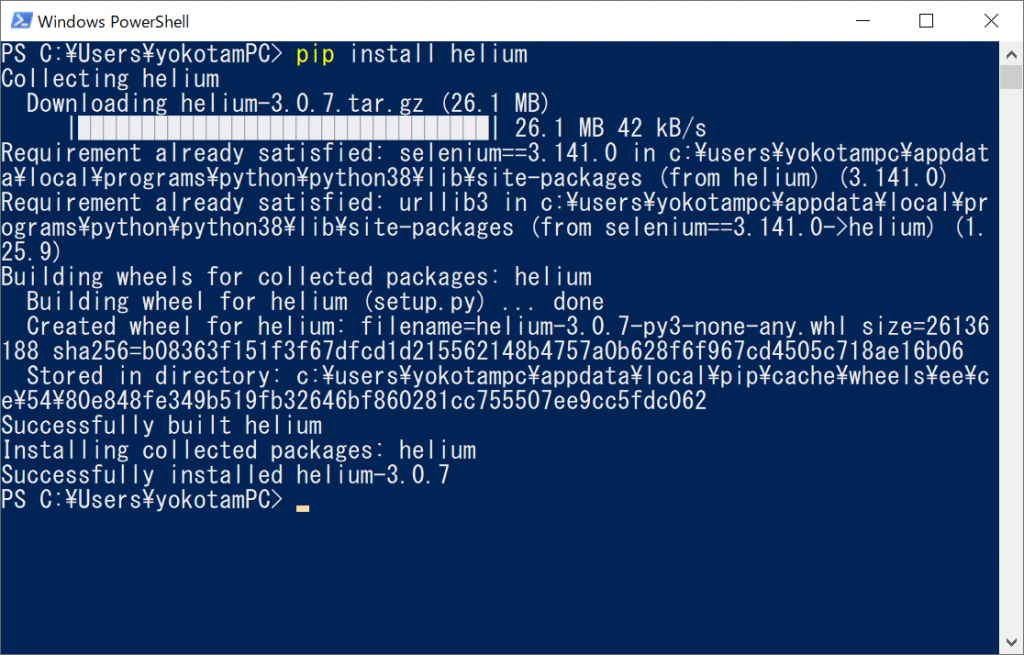
Heliumを使うには、インストールが必要です。Pythonがインストールされたマシンで「pip install helium」コマンドを実行すると、インストールできます。
②ChromeDriverのインストール
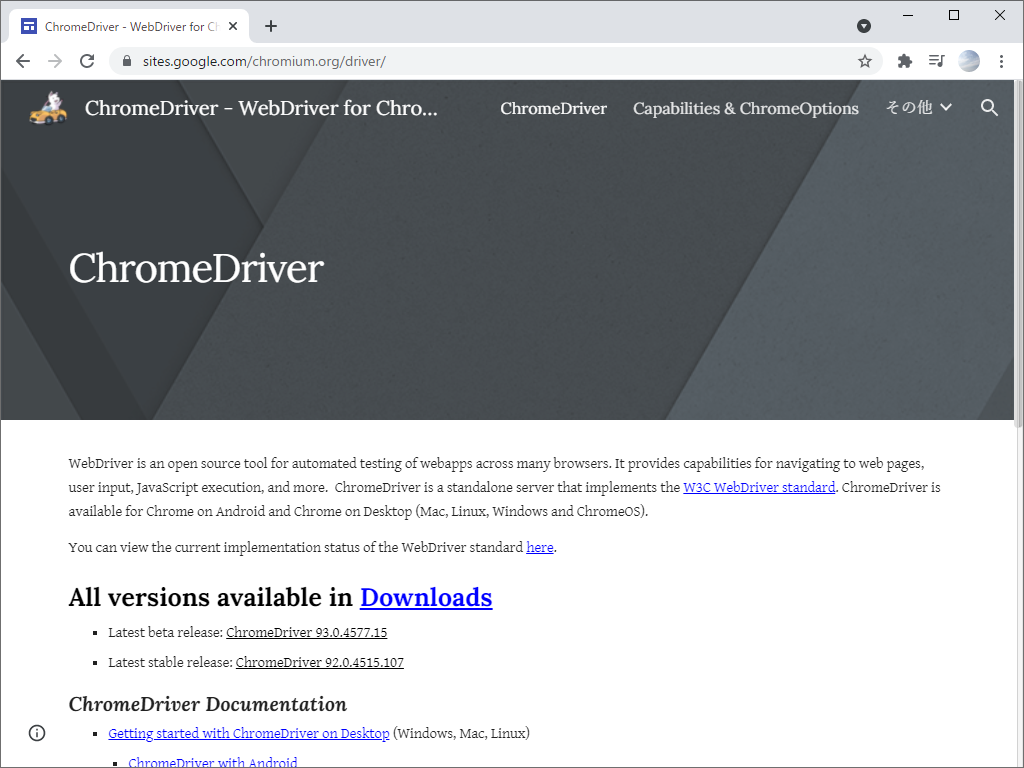
ChromeDriverを以下のサイトよりインストールします。インストールするバージョンは、使用しているChromeのバージョンと一致させる必要があります。
- ChromeDriver(https://sites.google.com/chromium.org/driver/)
ダウンロードしたファイル「chromedriver.exe」を配置したパスは、環境変数Pathに追加しておきます。
③コードを作成する~Chromeでの操作編~
Pythonのコードを作成します。まずは、Heliumのインポートが必要です。
from helium import *
Webページにアクセスするには、「start_chrome()」を使用します。引数には、URLを指定します。
start_chrome(“https://www.google.com/?hl=ja”)
テキストの入力は「write()」で行えます。ここでは、「Python」というキーワードでGoogle検索したいため、引数に「Python」を指定します。
write(“Python”)
ENTERキーの押下は、「press(ENTER)」で実施します。
press(ENTER)
ここまでのコードで、以下の3つの手順を実行できます。
- ブラウザで「https://www.google.com/?hl=ja」を開く
- フォームに「Python」を入力する
- Enterキーを押下
④コードを作成する~検索結果の取得編~
その後は、「Python」でGoogle検索した結果を取得するコードを書きます。Heliumでは、find_all(S(【CSSセレクタ】))を使うと、CSSセレクタの要素を取り出すことができます。検索結果を表すCSSセレクタは「div.tF2Cxc > div > a > h3」なので、検索結果の記事タイトルを取得するのは、以下のコードになります。記事タイトルは複数あるので、for文で順に取り出しています。
elements = find_all(S(“div.tF2Cxc > div > a > h3”))
for i in elements:
print(i.web_element.text)
最後に、プロセスが残らないように「kill_browser()」を呼び出します。完成したコードは以下です。なお、画面表示までの時間を考慮するため、time.sleepも使用しています。
import time
from helium import *
start_chrome(“https://www.google.com/?hl=ja”)
time.sleep(3)
write(“Python”)
press(ENTER)
time.sleep(3)
elements = find_all(S(“div.tF2Cxc > div > a > h3”))
for i in elements:
print(i.web_element.text)
kill_browser()
このコードを実行すると、以下の結果が得られます。
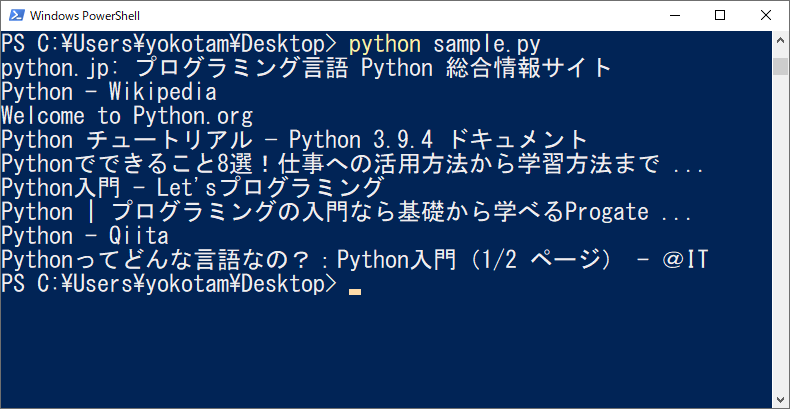
無事、1ページ目の検索結果を取得できました。
まとめ
Sleniumだとボタンのクリックなどの処理がもうすこし冗長になるので、Heliumのほうが、やはりすっきり書けるなという印象です。また手続き型っぽい記述でもないので、よりPythonらしい書き方ではないでしょうか。ただしEdgeに対応していないので、導入できないシーンもあると予想できます。対応ブラウザが広がるという期待も込めて、これからも動向を追っていきたいライブラリだなと感じました。
