当社はいわゆるIT書の編集プロダクションで、さまざまなIT書の編集、執筆、組版を、これまでに数百冊手がけています。元々よく作っていたのはアプリ(Excel、Wordなど)の操作解説書でしたが、ここ数年は案件の50%近くがプログラミング系の書籍です。近頃は「情報」科目が大学受験科目になるなど、プログラミングとコンピューターサイエンスの一般教養化が進んだせいか、主要顧客であるIT書の専門出版社さんに加えて、普段は文芸書やビジネス書などを手がける総合出版社さんから「プログラミング入門書を作ってほしい」という依頼も増えてきています。
そうなると、一般書とIT書の文化のギャップ——気にする場所の違いや、やってはいけないことの違い——を感じるケースも増えてきていまして、今回の記事では、「IT書って普通はどう作るのか」「どういう点がハマリやすいのか」について語ってみたいと思います。
誌面デザインのワナ ~コードはオマケでなく主役です
まずは見た目の問題からお話ししましょう。プログラミング入門書の経験が少ない場合にやってしまいがちなのが、ソースコードを可読性の低いデザインにしてしまうパターンです。プログラミング書籍においてソースコードは本文と同じぐらい重要なものであり、本文と同じぐらいの可読性が必要になります。ところが、プログラミング書のデザインに慣れていないと、表や図版と同レベルの、本文を補足する要素ととらえてデザインしてしまうケースが時々見られます。
下図はよくない例です。

- 強めの背景色と白抜き文字を組み合わせているため、コード(プログラミング言語の命令部分)の可読性が低い。
- 角張ったフォントでコンピューターっぽさを出しているが、コード用フォントが使われていない。そのため、文字の桁がそろわず、アルファベットや数字、記号の区別が付けにくい。
- 行番号とコードの境目がはっきりしない。
- コメント文が埋もれていてコードと区別しにくい(コメント文とは、#や//などの記号で始まる説明文。メモ代わりに使われるものでプログラムの実行時は無視される)。
IT書では、ソースコードは下図のようなデザインにすることが多いです。

- コード部分は、弱い背景色と黒文字の組み合わせにして可読性を高めている。
- コード用フォントが使われているので桁がそろっており、記号も区別しやすい。
- 行番号とコード部分の区別が明確になるよう背景色などを変えている。
- コメント文をグレーにしてコードと区別し、行頭をそろえている。
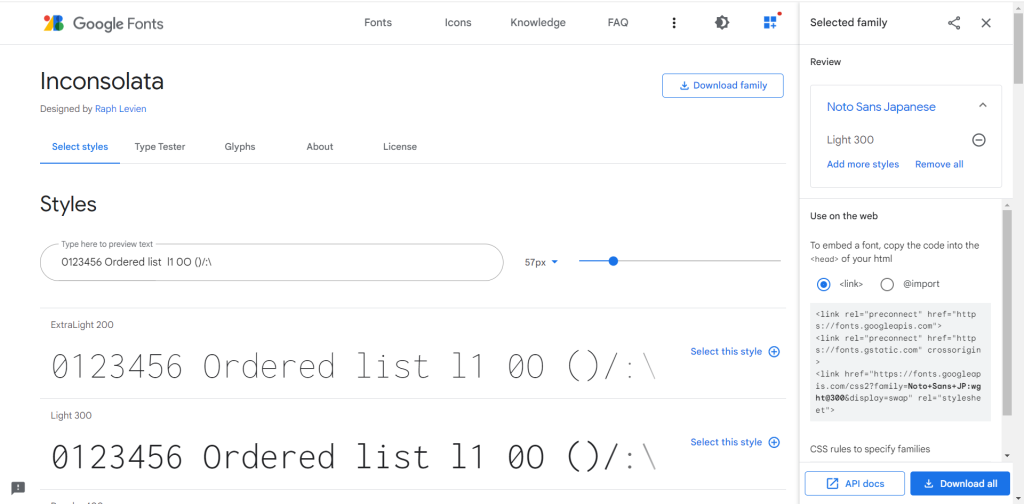
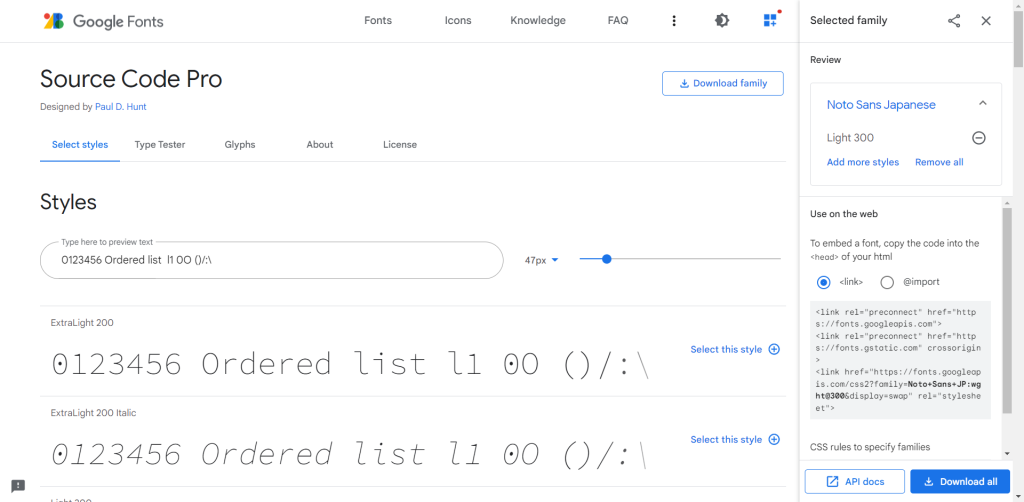
コード用フォントとは、プログラム開発用のエディタでも使われているプログラミング専用のフォントです。多くはWeb上で無料公開(正確にはオープンソースとして公開)されており、InconsolataやAdobe Source Code Proあたりが有名です。
コード用フォントは1文字の幅が均等な等幅フォントであり、「l(小文字のエル)と1(数字のいち)」「O(大文字のオー)と0(数字のゼロ)」といった似た文字を区別しやすくする工夫がほどこされています。1文字間違ってもエラーになるプログラミング向けのフォントです。
慣れている人なら、「行頭の数字は行番号だろう」「#から先はコメントだろう」などと区別できるのですが、入門者は当然慣れていませんから、行番号は行番号らしく、コメントはコメントらしくデザインしないといけないのです。
ちなみに、コメント部分を引き出し線付きに加工することもよくあります。

エンジニアさんの世界ではコメント文で説明を書くのは普通のことですが、コードを読み慣れていない人は説明ではなくコードの一部と思ってしまいがちです。そこでさらにひと工夫して、明らかにコードの一部に見えないようにしています。
ソースコードが壊れやすい理由 ~後からの変更にヨワイ
出版業界には昔から「世に校閲のタネは尽きまじ」という言葉があり、誤植をなくすのは簡単ではない、いいかえると「ギリギリまで赤字を入れるほどよい本になる」という思想が根強くあります。これはビジネス書や実用書などでは正しいとされていますが、そのノリでソースコード部分にガンガン赤字を入れると、よい本になるどころか、サンプルファイルが動かない致命的な間違いだらけの本になる危険が大きいのです。
説明のために、一般的なチュートリアルタイプのプログラミング入門書の作り方を説明しましょう。チュートリアルタイプでは、サンプルコードが長くなってくると、「少しずつコードを足す」「実行結果を確認する」を繰り返しながら説明していきます。
下図の本は、左ページでイラストを複数枚横に並べる方法を説明し、右ページでソースコードにいくらか書き足して、斜め下にずらしながら並べる方法を説明しています。

こういう原稿を書くには、「ソースコードを少し書き足す」「実行結果の画面ショットを撮影」を少しずつ繰り返し、それらを貼り付けながら原稿データを作成していきます。
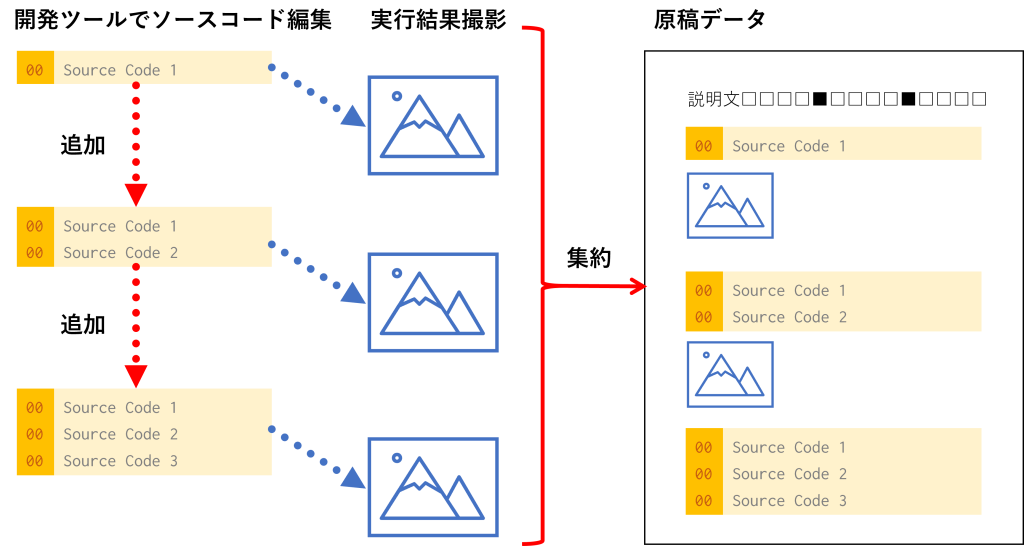
この段階の原稿に貼られたソースコードは、ミスがほとんどない状態です。なぜなら、実行結果の画面ショットを撮影するためにはプログラムを実行しなければならず、撮影できたということは、少なくとも「プログラムが動かないレベルのミスがない」状態だからです。
初校や再校の段階でゲラに赤字が入った場合、修正が入った段階までソースコードの状態を戻さないと、画面ショットを再撮することができません。また、途中段階でソースコードを修正した場合、修正した箇所から先はすべて直す必要も出てきます。「赤字を入れた場所だけ直せば済む」シンプルな世界ではないのです。
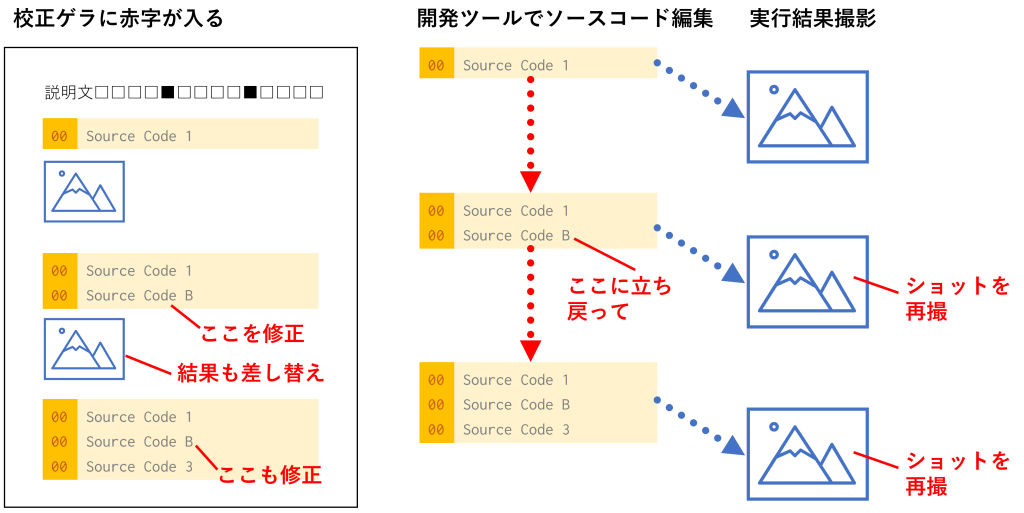
ここで注意が必要なことがもう1点あります。プログラミング言語は、知らない人にとっては意味不明な英語モドキと記号の羅列なので、修正ミスが非常に発生しやすいことです。lと1、Oと0、2とZ、:(コロン)と;(セミコロン)などの打ち間違えや、全角と半角の取り違え、挿入する場所を間違えるなど、ありとあらゆるミスがありえます。
そのため、原稿段階では少なくとも動くソースコードだったものが、初校以降で行った修正の結果、動かないものになってしまう可能性があります。
とはいえ、初校以降でまったく修正がないということはありえないので、初校以降のどこかの段階で、ゲラを見ながら実際にプログラムを動かす動作検証を行います。ただし、動作検証はそれなりに時間がかかるので、何回も実施できません。そのため、終盤の修正を可能な限り減らし、構成が変わるような大きな修正はなるべく原稿段階で行うことが重要です。
当社では、原稿段階で仮組みを作り、先に大きな修正を済ませておくワークフローを試みていますが、それについては後ほど改めて説明します。
わかりやすくしたつもりが間違いを生むワナ
IT書の中でもプログラミングは、本を1、2冊読んだぐらいで理解できるほど簡単ではありません。特に入門書は、読者が混乱しないようあえて説明していない部分も多いので、入門書を読んだだけでは学べないこともたくさんあります。そのため、知識不足で編集した結果、わかりやすく修正しようとして間違いにしてしまうケースもわりと見受けられます。
たとえば、以下は「戻り値」というものを説明する定型的な文です。文中に出てくる「関数」というのは、非常に簡単に説明すると、プログラムの命令の一種です。
「戻り値」とは、関数の結果として返す値のことです。
ちょっと回りくどくてわかりにくいようにも思えますね。なので、簡潔になるよう直してみます。
「戻り値」とは、関数の結果です。
これでも一応間違いではありません。ただし、さらにわかりやすくしようと思って、次のような説明を足すと間違いになってしまいます。
「戻り値」とは関数の結果です。例えば、print関数がコンソール画面に表示する文字列や、plot関数が描画するグラフも、関数の結果という意味では戻り値です。
戻り値は関数の結果の一種ですが、関数の結果すべてが戻り値ではありません。戻り値は、関数とデータを受け渡しするための仕組みです。例えば数値の小数点以下を四捨五入するround関数であれば、四捨五入した結果が戻り値として返されます。画面に何かを表示する場合は、データの受け渡しが発生していないので、それを戻り値だと説明すると間違いになってしまうのです。
こういうややこしい事情があちこちに隠れているので、文章がいくらか回りくどいと思っても、感覚的な読みやすさだけで直すのは禁物です。
異文化交流による行き違い
プログラミングと書籍の世界は、いろいろな面で異なります。例えば、人文書の世界では「何が正しいか」は人によるので、正解が出ないものもたくさんあります。「何をいうか」より「誰がいうか」が重要な世界でもあります。
それに対して、プログラミングは比較的「正解」がある世界です。まず、「プログラムがちゃんと動くか動かないか」というコンピューターによる審判があります。偉い人がどういっても、動かないものは正しくないです。また、たいていのソフトウェアには公式のリファレンスがあり、そこに書いてあることは原則的に正しいとされます。それでも実践に近づくにつれて「正しい」が人それぞれになっていきますが、基礎や入門のレベルでは「正しい」は明確といっていいでしょう。
このように世界が大きく違うため、一般書の編集者とITエンジニア(プログラマー)の出会いが不幸なものになる場合があります。お互いに「あいまいなことばかりいって、何をしてほしいのかわからない」「細かいことばかりいって、何でも否定してくる」と感じ、やがて「いくらいってもイメージどおりに書いてくれない」「よくわからない理由で勝手に直される」と不信感が高まり、結果として書籍の完成に至らないこともあります。
当社は、長年本職のITエンジニアさんと、出版社との間に立って仕事をしてきており、IT書の編集制作がある種の異文化交流であることを知っています。エンジニア出身のスタッフを編集者にしているので、両者の間に立って進行するノウハウがあります。
なので、当社にIT書の編集や組版をご依頼されるにあたっては、初期の段階からお任せいただければ、スムーズかつヨイ感じに完成まで持っていく可能性を高められるかと思います。
当社の仮組みワークフロー
先ほど、プログラミング書を初校以降で直しすぎるのは禁物、というお話をしました。しかし、テキスト原稿の段階で、仕上がりをイメージしながら編集するというのも現実的ではありません。そこで当社では、Markdownで書かれた原稿を仕上がりの紙面に似たPDF(通称「仮組み」)に変換し、その「仮組み」を見ながら初期編集を行うというワークフローを採用しています。
Markdownとは、オープンソース系のエンジニアさんがよく使っている文書形式で、IT書では数年前からMarkdownの原稿が増えています。テキストファイル内に#や*などの記号を入れて書式を表すシンプルなもので、HTML(Webページの記述言語)に簡単に変換できるという特徴があり、Webページ用の技術を使って装飾し、ページ分割すると、DTPソフトで作ったものに近い紙面を自動作成できます。
文字サイズや行送りなどの設定を、実際の紙面デザインに近づけて設定しておけば、9割程度の精度のゲラを自動作成でき、この段階でページ数などを見積もることができます。Markdown原稿から直接生成するので、通常のDTP工程に比べて修正の手間が大幅に軽減するだけでなく、人為的なエラーが混入する余地もありません。元はテキストデータですから著者&編集者がいじることもできるので、この段階で大きな変更は可能な限り済ませておきます。
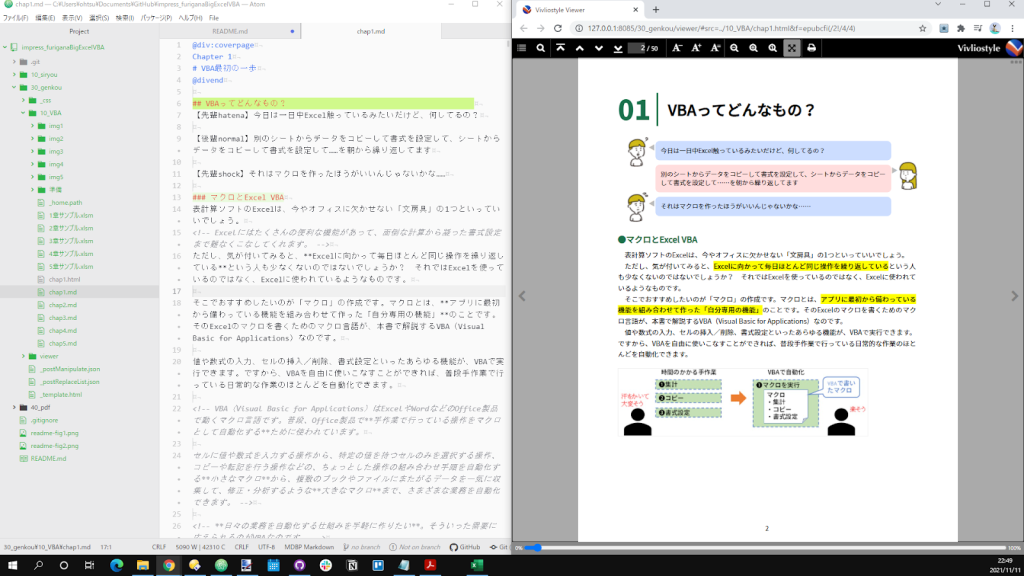
参考:Markdownプレビューツールを使った新しい編集・制作フローのご提案
参考:MarkdownプレビューツールをAtomパッケージ化しました
仮組みで大まかな内容を固めたあとは、通常の書籍と同じくDTPソフト(InDesign)に流し込んで、初校を作成していきます。スクリプトを使っていくらか自動で組むようにはしていますが、初校から先は通常どおりなので、修正の手間は変わらなくなります。仮組み段階でどれだけ内容をフィックスできるかが、致命的ミスを減らし、効率をアップするカギとなるわけです。

また、仮組みをそのまま版下にするCSS組版にも取り組んでいます。Webページと同じ装飾技術が使えるので、表現力は従来のDTPに劣りませんが、CMYKが使えないなどの制限(1色にするかRGBベースのフルカラーにするしかない)もあります。その代わり、通常のDTPでは手間がかかる組版を半自動で行える、LaTeX互換の数式を入れられるなどのメリットがあります。
以下は、CSS組版でマンガ風に組んだシリーズです。Markdown原稿をマンガ形式になるよう半自動組版し、書き出したPDFを印刷所に入稿しています。

プログラミングやコンピューターサイエンスの重要性が年々高まっている現在、出版側もその需要に応えていかないといけないという思いがつのります。また、ITが一般化するに伴って、IT書にもまだまだ進化の余地があると感じます。
そのためにも、まずはITという題材に合った制作手法を取ることが重要です。写真集やマンガに作りやすい手法があるように、IT書にも適した作り方があります。それを踏まえた上で新たな取り組みをしないと、進化どころか同じところで足踏みするだけです。
私たちがその一助となれれば幸いです。
