「ふりがなプログラミング」シリーズに久々の新刊が登場します。人気の生成AIを使って、ムチャ振り気味な業務を自動化しながら、Pythonを学ぶという一石二鳥気味な本です。
生成AIと一緒に学ぶ Pythonふりがなプログラミング(インプレス社サイトへ)

AI+プログラミングの書籍はすでにいろいろ出ていますが、本書はコード生成はAIに任せて、「業務整理→プロンプトの組み立て方」と「プログラムを読解しながらエラー原因を探す方法」に説明を注力した結果、既刊書とはまた違った方向性を示せたのではないかと思います。


今回はその紹介を兼ねて、本書のコンセプトどおりに業務自動化できることを証明するために、出版業界では切実な問題である「入稿直前の索引チェック」を自動化してみます。
「索引チェック」の要件を整理する
索引チェックというのは、言葉通り索引ページと実際のページ上のキーワードが一致しているかを照合していくことですが、手作業でどうやるかを整理すると
- 索引からキーワードとページのセットを取り出す。
- カンマでまとまっているページは、分割してその数だけ繰り返す。
- そのページのPDFを開き、キーワードが載っているか調べる。
となります。
索引データはテキストファイルやExcelファイルなどに移したほうが処理しやすいので、まず、入稿用PDF一式が入ったフォルダ内に、Excelファイルを作成します。注:このプログラムは単ページPDFでなければ正しく動作しません! 入稿用のX-4のPDFなどをそのまま使ってもOKです。
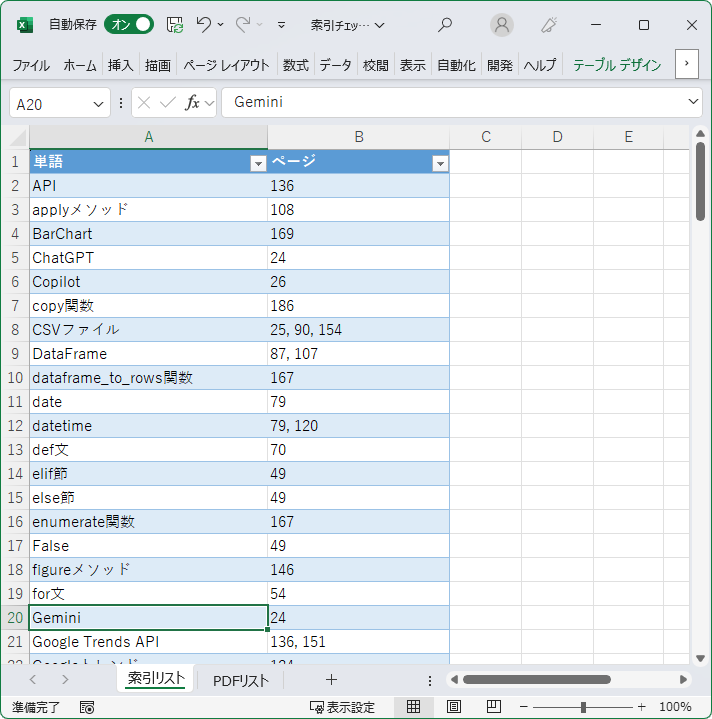
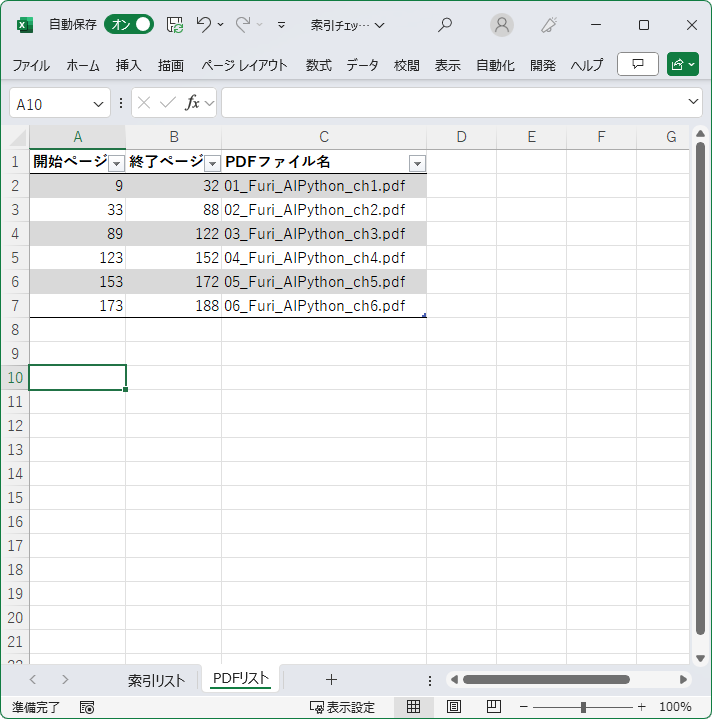
索引PDFからテキストをコピペして表を作ります(単純化のために、あ行、か行などは手作業で取り除く)。別のシートには、各PDFの開始ページと終了ページを入力しておきます。
手作業でやることをテキスト化するイメージで、プロンプトをまとめます。見るとわかりますが、アルゴリズムを日本語の文章にしたようなものです。手順をまとめたらたまたまそうなったとか、本シリーズの「読み下し文」に似ているからとか、理由はいくつかあるのですが、本書は生成AIだけでプログラムを完成させるのではなく、「生成AIが作ったプログラムを読解して自力でエラーを解決する」コンセプトなので、生成用プロンプトもアルゴリズムに近づけたほうが結果が制御しやすかろうと思います。
次の仕事をするPythonのプログラムを生成してください
###
・索引チェック用シート.xslxを開く
・「索引リスト」シートから表を読み込む。これを「kwlist」とする。
・「PDFリスト」シートから表を読み込む。これを「pdflist」とする。
・kwlistから1行ずつ読み込み、以下を繰り返す。
・「ページ」列をカンマで分割し、そのリストの数だけ以下を繰り返す。
・リストの要素を整数にしたものをtargetpageとする。
・pdflistから、「開始ページ」列 <= targetpage <= 「終了ページ」列を満たす「PDFファイル名」を探す。
・「PDFファイル名」のPDFを開く。
・targetpageのページを探し、そのページ内にkwlistの単語が存在するか調べる。
・存在しない場合は、「report.txt」に次の情報を保存する。
PDFファイル名 targetpage kwlistの単語これだと「実際にコードを書くのと手間が変わらないのでは?」と思う方もいるかもしれませんが、そんなことはありません。
私自身がそうなのですが、たまにしかプログラムを書かない「タマグラマー」にとって、一番困るのは「ライブラリやAPIの使い方を知らない or 前に調べたけど忘れてしまう」ことです。言語の文法だけ理解していても、辞書なしで英語文法だけ勉強したようなもので、ほしいプログラムは作れないんですね。
生成AIを使う場合、「○○.xlsxを開け」「PDFを読み込め」という大雑把な指示するだけで、勝手にpandasやopenpyxl、PyMuPDFなどのライブラリ(パッケージ)を使ったコードを書いてくれます。これらを自力で調べていたら、完成まで数時間では済まないと思います。
ところで、このプロンプトをCopilotに与えてみたところ、なぜか「モジュールのインポートに失敗しました」といってきました。このメッセージは出るときと出ないときがあって、法則性はちょっとわかりません(GPTのCode Interpreterを連想させますが謎です。書籍の執筆中は一度も出ませんでした。)。

どうでもいいことなので、無視してコードを生成するよう指示すると、ちゃんとプログラムを作ってくれます。

動くまでエラーを直す
以下は、最初に出力されたプログラムですが、これをPythonで実行するとエラーが発生します。
import pandas as pd
import fitz # PyMuPDF
# Load the Excel file
file_path = '索引チェック用シート.xlsx'
kwlist_df = pd.read_excel(file_path, sheet_name='索引リスト', engine='openpyxl')
pdflist_df = pd.read_excel(file_path, sheet_name='PDFリスト', engine='openpyxl')
# Open the report file to write missing keywords
with open('report.txt', 'w') as report_file:
# Iterate over each row in kwlist
for index, row in kwlist_df.iterrows():
keyword = row['単語']
pages = row['ページ'].split(',')
for page in pages:
targetpage = int(page)
# Find the corresponding PDF file in pdflist
pdf_row = pdflist_df[(pdflist_df['開始ページ'] <= targetpage) & (pdflist_df['終了ページ'] >= targetpage)]
if not pdf_row.empty:
pdf_filename = pdf_row.iloc['PDFファイル名']
# Open the PDF file
pdf_document = fitz.open(pdf_filename)
# Check if the keyword exists in the target page
page_text = pdf_document.load_page(targetpage - 1).get_text()
if keyword not in page_text:
# Write the missing keyword information to the report file
report_file.write(f"{pdf_filename} {targetpage} {keyword}\n")
# Close the PDF file
pdf_document.close()細かい型の問題もあるのですが、一番てこずったのがpandasのilocメソッド(アイロック、おそらくindex locateのような意味)を使っている部分で、プロンプトで何度指示を出しても解決してくれませんでした。「ilocメソッドの使い方」を生成AIに聞くと、「行や列をインデックス番号で指定する」と答えるのですが、プログラム中ではなぜか列名の文字列を指定しています。ilocとlocという名前が似たメソッドがあるせいかもしれません。
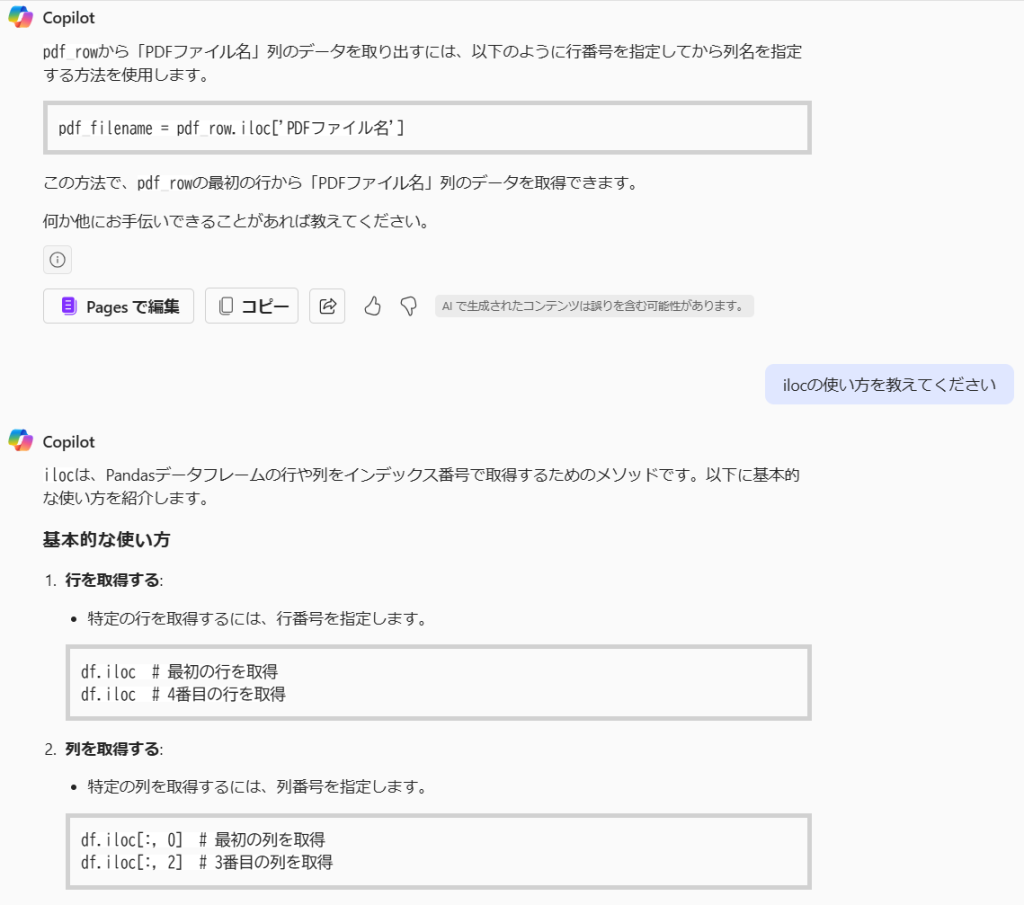
しかたないので、インデックス番号を指定する形に手作業で変更しました(本当は列名で値を取得するメソッドに変更したほうがよさそうですが、実際に入稿前で時間が足りなかったので……)。
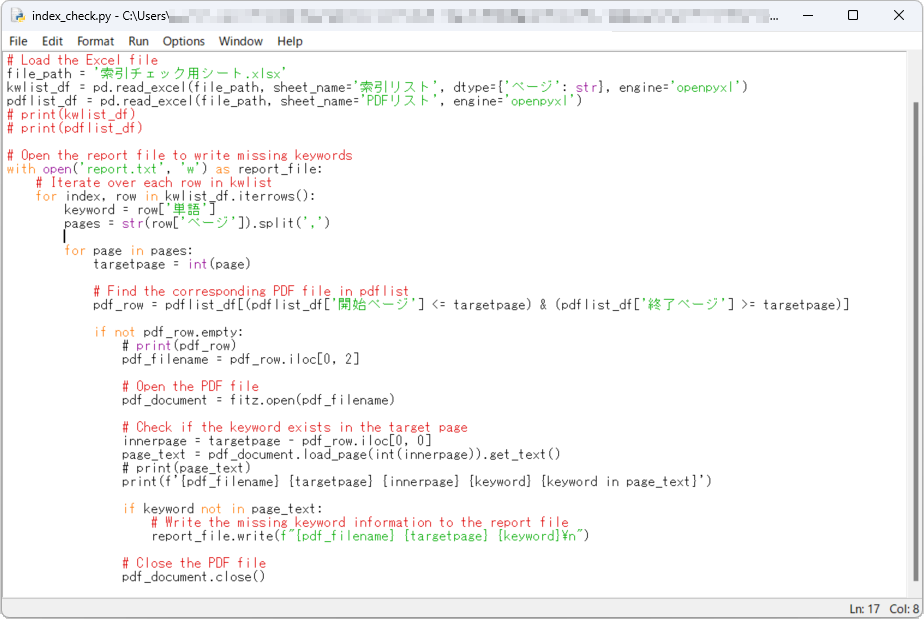
以下は最終的に完成したプログラムです。ところどころ型関連の問題があったので、微調整しています。とはいえ、見ての通り大きな違いはありません。
import pandas as pd
import fitz # PyMuPDF
# Load the Excel file
file_path = '索引チェック用シート.xlsx'
kwlist_df = pd.read_excel(file_path, sheet_name='索引リスト', dtype={'ページ': str, '単語': str}, engine='openpyxl')
pdflist_df = pd.read_excel(file_path, sheet_name='PDFリスト', engine='openpyxl')
# print(kwlist_df)
# print(pdflist_df)
# Open the report file to write missing keywords
with open('report.txt', 'w') as report_file:
# Iterate over each row in kwlist
for index, row in kwlist_df.iterrows():
keyword = row['単語'].strip()
pages = str(row['ページ']).split(',')
for page in pages:
targetpage = int(page)
# Find the corresponding PDF file in pdflist
pdf_row = pdflist_df[(pdflist_df['開始ページ'] <= targetpage) & (pdflist_df['終了ページ'] >= targetpage)]
if not pdf_row.empty:
# print(pdf_row)
pdf_filename = pdf_row.iloc[0, 2]
# Open the PDF file
pdf_document = fitz.open(pdf_filename)
# Check if the keyword exists in the target page
innerpage = targetpage - pdf_row.iloc[0, 0]
page_text = pdf_document.load_page(int(innerpage)).get_text()
# print(page_text)
print(f'{pdf_filename} {targetpage} {innerpage} {keyword} {keyword in page_text}')
if keyword not in page_text:
# Write the missing keyword information to the report file
report_file.write(f"{pdf_filename} {targetpage} {keyword}\n")
# Close the PDF file
pdf_document.close()
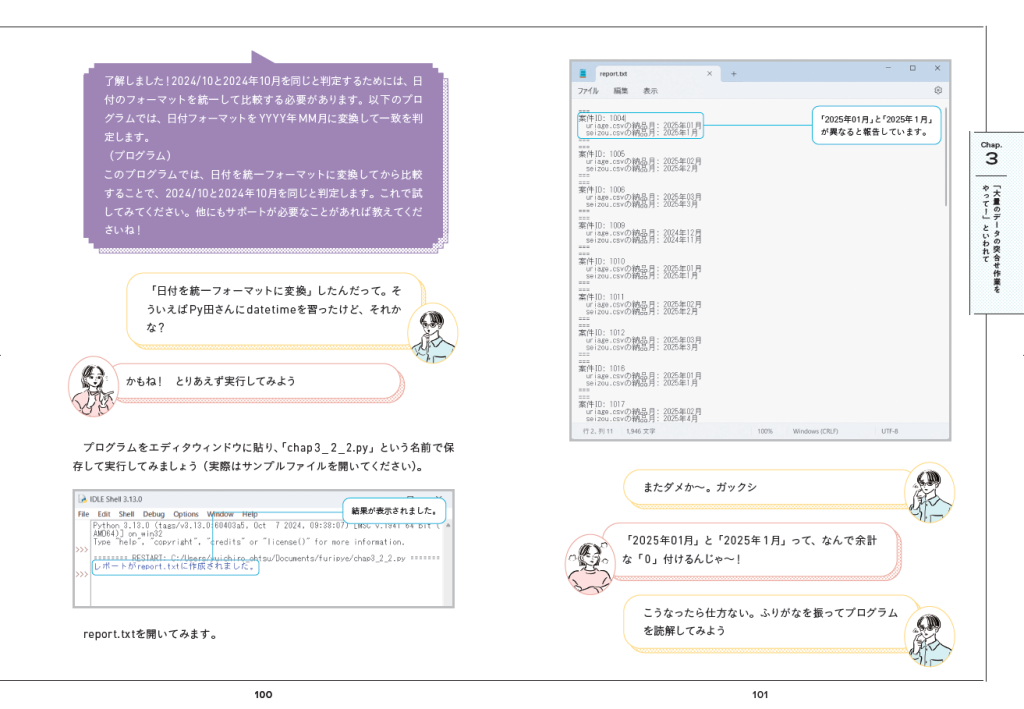
PythonコマンドかIDLEを使って実行すると、しばらく検索したあと、report.txtが書き出されます。
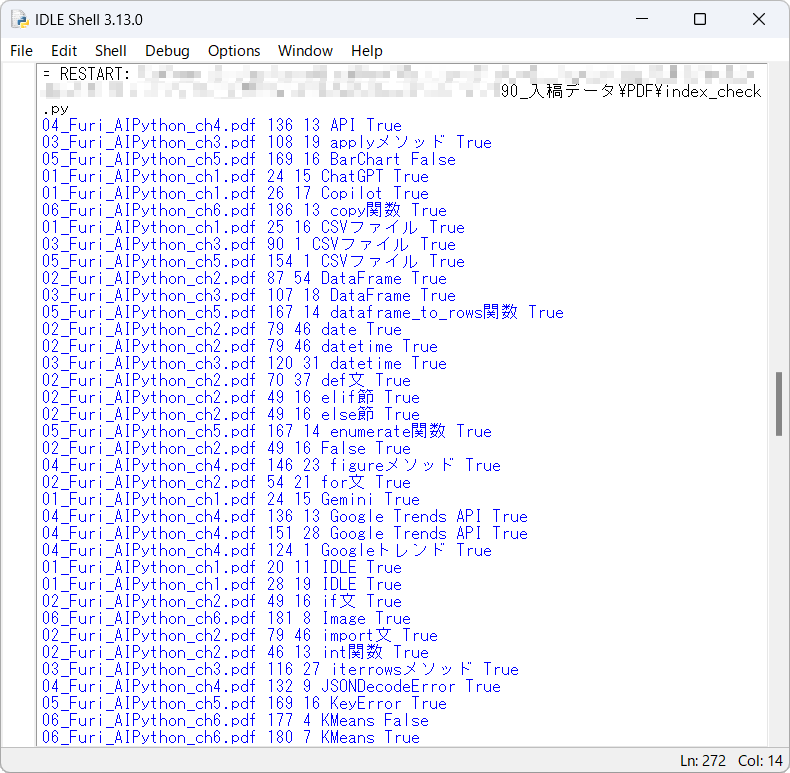
書き出されたreport.txtを開くと、該当ページ内にキーワードが見つからなかった部分が列挙されています。レポート内で指摘されていても実際に間違っているとは限らず、PDF上でキーワードが折り返されている場合、妙に字間が開いている場合、文字を微妙に変更している場合(「プログラムを実行する」→「プログラムの実行」など)も指摘されます。少ないより多いほうがいいので、実用上は問題ないはずです(改行を消してから比較する、など改良の余地はありそうですが)。
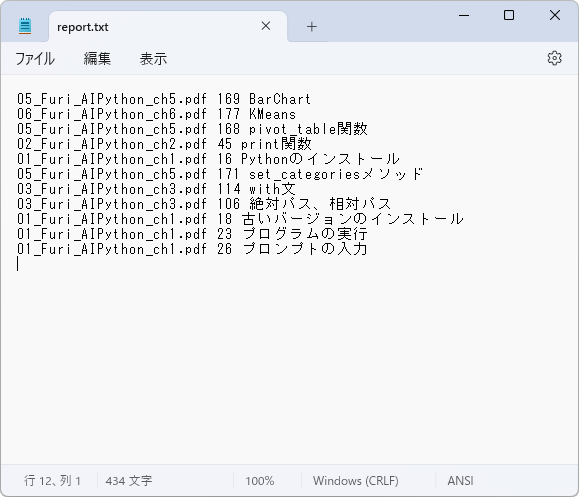
とまぁこんな感じで、意外と手軽に業務に役立つプログラムが作成できます。
書籍内では、「プロンプト作成のコツ」「生成されたプログラムを読み解くコツ」「エラー原因を探して解決するコツ」を体験学習できるようまとめてみましたので、ご興味がある方はぜひご一読いただけると幸いです。
